Trained convex heads are published on the
Hugging Face Hub.
Each checkpoint includes a CVXNNLangDetectHead (model.pkl) that pairs
with its corresponding frozen ASR backbone. All models load in a single line via
hf_hub_download.
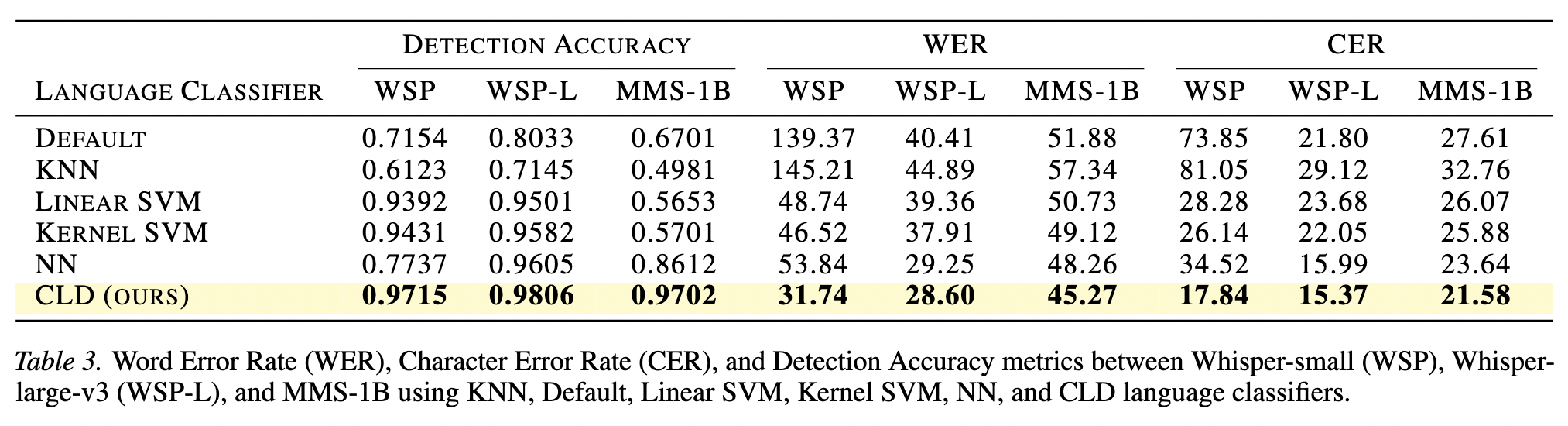
| Model |
Backbone |
Languages |
Det. Acc |
WER ↓ |
CER ↓ |
Hub |
cld-whisper-small-5lang |
whisper-small |
enhiidmszh |
0.98 |
48.23 |
27.47 |
🤗 Hub |
cld-whisper-large-v3-5lang |
whisper-large-v3 |
enhiidmszh |
0.98 |
31.11 |
19.81 |
🤗 Hub |
cld-mms-1b-5lang |
mms-1b-all |
enhiidmszh |
0.96 |
48.10 |
23.47 |
🤗 Hub |
cld-whisper-small-enzh
(100–10,000 samples/class) |
whisper-small |
enzh |
0.99–1.00 |
— |
— |
🤗 Hub |
Loading from the Hub
For the five-language models, use the following snippet:
import numpy as np
from huggingface_hub import hf_hub_download
from jaxcld import ASRModel, CVXNNLangDetectHead
languages = ["en", "hi", "id", "ms", "zh"]
# 1) Load the frozen base ASR model
asr = ASRModel.from_pretrained("openai/whisper-small", config={"languages": languages})
# 2) Download the convex head from the Hub and load it
head_path = hf_hub_download("williamhtan/cld-whisper-small-5lang", "model.pkl")
head = CVXNNLangDetectHead.load(head_path, asr)
# 3) Attach the head
asr.set_lang_detect_head(head)
# 4) Grab one clip from the dataset's test split
from datasets import load_dataset
sample = next(iter(load_dataset("williamhtan/cld-multi-dataset", split="test", streaming=True)))
audio_16k_mono = sample["audio"]["array"] # (T,) float waveform, 16 kHz mono
# 5) Predict
pred_langs, pred_texts = asr.predict(audio_16k_mono)
print("true:", sample["lang"], "| pred:", pred_langs[0], "| text:", pred_texts[0])
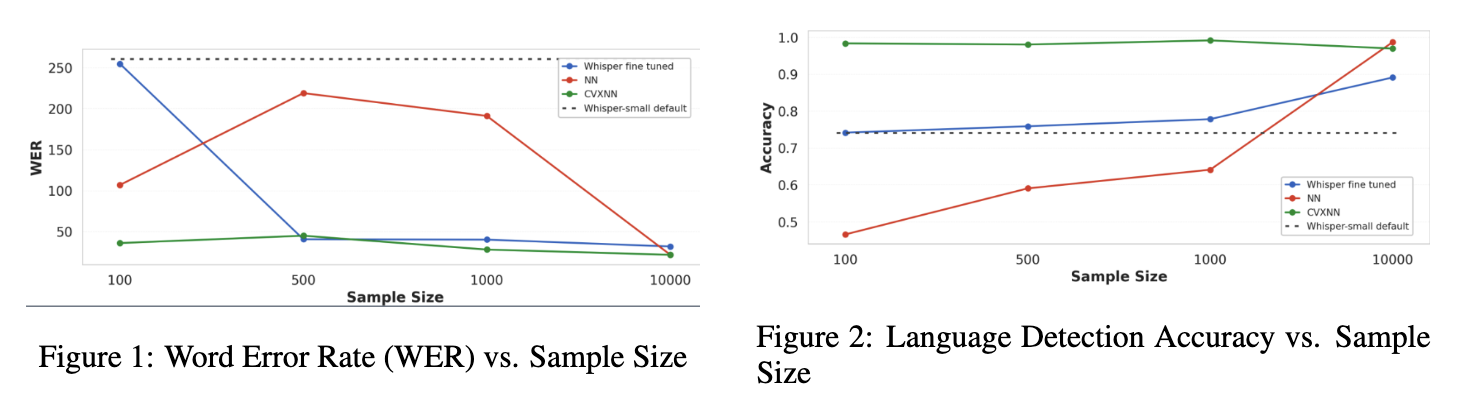
For the low-resource binary model, specify the samples-per-class subfolder corresponding to
your training budget:
# Example: load the 1,000-samples-per-class checkpoint
head_path = hf_hub_download("williamhtan/cld-whisper-small-enzh", "1000/model.pkl")
Available subfolder options are 100, 500, 1000,
and 10000, corresponding to the per-class training budgets
evaluated in the sample-efficiency experiments.
{kind=link}